
지난 글에 조화분해에 대해 간략하게 설명하였고, 이번에는 실제 데이터와 t-tide를 활용하여 조화분해를 해보도록 하겠다.
[조화분해] 파이썬을 활용한 조화분해(harmonic analysis) - 1. 조화분해란
오랜만에 본업으로 돌아와, 이번에는 조화분해에 대해 알아보도록 하겠다. 학위과정 중에는 matlab의 t-tide를 주로 이용했었는데, matlab을 활용할 수 있는 여건이 되는 기업들은 많지 않다. 파이썬
ihatenumber.tistory.com
1. 조위 관측정보
조위 정보는 국립해양조사원 바다누리 해양정보 서비스에서 다운로드가 가능하다. 별도로 관측한 조위 정보여도 무방하다. 이번 글에서 활용한 조위자료는 인천 조위관측소의 2024년 11월 자료이며, 실제 데이터는 아래 우측 사진처럼 1분단위 시계열로 구성되어 있다.


이전 글에서 설명했듯이, 조석 조화분해에 필요한 변수는 xin, dt, stime, lat 등이 있으며, 세부 내용은 코드나 위 링크를 참고하면 된다.
2. 조위 정보 Read & 전처리
텍스트 파일인 조위 자료는 판다스 라이브러리 read_csv를 이용하여 불러온다. 판다스 read_csv 사용 및 옵션 관련 내용들은 이전에 작성한 아래 링크를 참고하면 된다.
[파이썬] 4-1. 조위 자료 분석 - 텍스트 읽기, pandas, read_csv, 인코딩 및 옵션
파이썬으로 실제 데이터를 읽고 처리하는 방법에 대해 소개해볼텐데, 첫번째로 해양데이터 중 가장 기초적인 정보에 해당하는 조위정보를 읽어오는 과정을 진행해보려한다. 조위정보는 국립해
ihatenumber.tistory.com
시간 정보는 2024/11/01 00:00:00과 같이 yyyy/mm/dd HH:MM:SS의 형식의 텍스트다. 따라서 이를 datetime 라이브러리 strptime을 활용하여 datetime 형태의 시간으로 바꿔줘야 한다. 또한, 조위관측소 데이터의 헤더가 한글로 되어 있고, 데이터 중 첫번째 컬럼이 조위정보이므로 첫번째 컬럼만 'tide'로 컬럼명을 변경하고 이 컬럼만 't_tidal' 이라는 개별변수로 추출하였다. 또한 관측정보에 결측이 있을 수 있고, 이 결측값은 한글 또는 공백의 텍스트로 되어 있기 때문에 이 값을 빈 값 처리하고 숫자형태의 배열로 바꿔줘야 한다. 정리해보면, 아래와 같다.
- read - pandas의 read_csv 활용
- 시간(텍스트 형식) datetime으로 변환 - datetime.strptime 활용
- 컬럼명 변경 - rename 활용
- 조위데이터(텍스트 형식) 숫자로 변환 및 결측(공백 또는 텍스트) 값 nan처리
- numpy형태의 배열로 변환
위 과정은 마찬가지로 이전 글에 자세히 소개했었으니 아래 링크를 참고하면 된다.
[파이썬] 4-1. 조위 자료 분석 (2) - dataframe의 칼럼명/열이름/헤더 수정 rename, 결측값 숫자변환
지난번 글에서는 판다스(pandas)의 read_csv를 활용해 데이터를 읽어오는 부분까지 진행했었다. 오늘은 읽은 데이터 중 특정 열을 뽑아내서 분석하기 위한 전 단계인 데이터 추출 및 칼럼명(헤더) 수
ihatenumber.tistory.com
datetime 및 strptime은 아래 링크를 참고하면 된다. 또한, 위 과정을 아래 코드로 첨부하였다.
[파이썬] 4-1. 조위 자료 분석 (3) - datetime을 활용한 문자 숫자 날짜변환, 날짜/시간 연산, 수치모델
이번에는 datetime을 활용해서 시간 데이터를 변환하고 처리하는 방법에 대해 다뤄보도록 하겠다. 대부분의 txt파일 또는 csv형식의 ascii 파일 데이터는 문자열로 정보가 입력되어 있기 때문에 이를
ihatenumber.tistory.com
path = '파일경로 입력'
fname = '관측정보 파일명 입력'
t_data = pd.read_csv(path + '/' + fname, sep='\t', header=3, encoding='cp949')
## 경로 및 파일명, 구분자, 헤더, 인코딩 형식 등 옵션 입력 ##
aaa = t_data.columns
t_data.rename(columns={aaa[0]:'otime', aaa[1]:'tide'},inplace=True)
## 컬럼명 변경 - 첫번째 컬럼(시간), 두번째 컬럼(조위)
t_time = [datetime.datetime.strptime(t_data.otime[i],'%Y/%m/%d %H:%M:%S') for i in range(len(t_data))]
## 텍스트 형식의 시간을 datetime 형식으로 변환 ##
t_tidee = pd.to_numeric(t_data.tide,errors='coerce')
t_tidal = np.array(t_tidee).astype(float)
## 텍스트 형식 조위를 숫자배열로 변환 및 빈 값 처리
다운로드 받은 조위데이터의 형태에 따라 옵션을 달라질 수 있겠지만, 전체적인 과정은 크게 다르지 않으며, 위와 같이 데이터를 읽고 전처리를 하고 나면, 아래와 같이 시간과 조위 시계열을 뽑아낼 수 있다.

3. t_tide 실행
t_tide를 실행하여 조화분해를 하기 위해서 xin, dt, stime, lat을 입력해야 한다. xin은 위에서 뽑아낸 조위 시계열인 t_tidal이고, dt는 시간간격인 1분인 1/60을 입력하면 되며, stime은 데이터의 시작시간인 t_time[0]을 입력하면 되고, lat은 해당 데이터의 관측지점 위도인 37.451944를 입력하면 된다.
- xin - 조위 시계열 (t_tidal)
- dt - 시간 간격 (1분, 1/60)
- stime - 시작 시간 (t_time[0])
- lat - 관측지점 위도 (37.451944)
hm_result = t_tide(t_tidal, dt=1/60, stime=t_time[0], lat=37.451944)
조화분해 결과를 hm_result라는 변수로 저장한다. 그럼 위와 같이 코드를 입력하면 되며, 아래와 같이 조화분해 결과가 나타나고 hm_result에 결과가 저장된다.

4. 조화분해 결과
위 사진의 조화분해 결과를 보면, 총 7개의 컬럼으로 되어 있는 것을 확인할 수 있다. 컬럼명은 왼쪽부터 순서대로 tide, freq, amp, amp_err, pha, pha_err, snr이며, 이는 분조명, 주기, 진폭, 진폭 95% 신뢰구간, 위상, 위상 95% 신뢰구간, 신호 대 잡음비이다.
또한, 조화분해결과인 hm_result를 출력해보면, 아래 사진과 같이 각 조화상수 및 정보들이 변수로 저장되어 있다.

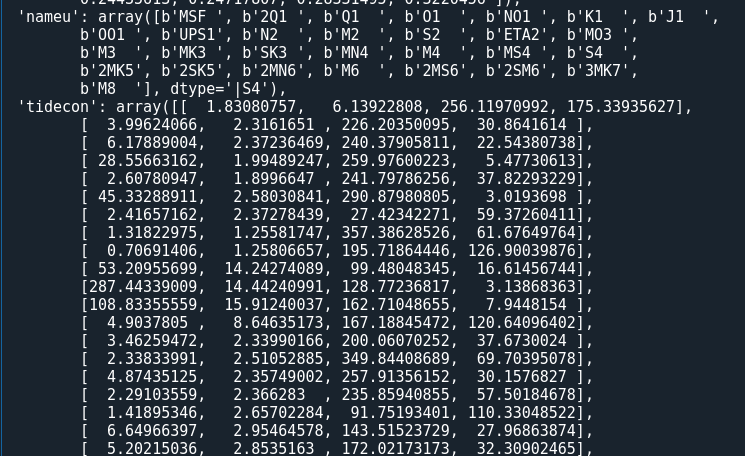
5. 예측조위 생산
조화분해를 통해 얻어낸 각 분조의 조화상수를 이용하면 예측조위를 생산할 수 있다. 본 글 최상단 링크에 걸어둔 이전 글에 소개했던대로 예측조위는 t_predic 함수를 활용하며, 아래 그림과 같이 필요한 변수는 t_time, names, freq, tidecon, lat, ldype 등이 있으며, 이는 각각 예측시간, 분조이름, 주기, 조화상수, 위도, nodal 적용 유무이다.

- t_time - 예측하려는 시간. 기간 시계열로 입력
- names - 분조명. 조화분해를 통해 얻어낸 결과 그대로 입력
- freq - 분조별 주기. 조화분해를 통해 얻어낸 결과 그대로 입력
- tidecon - 분조별 조화상수. 조화분해를 통해 얻어낸 결과 그대로 입력
- lat - 예측하려는 지점의 위도 입력
- ltype - 노달 유무. nodal 입력 또는 입력하지 않아도 무방(자동적용)
위 조화분해 과정에서 조화분해 결과를 hm_result로 저장했었다. 따라서, names, freq, tidecon은 hm_result 안에 'nameu', 'fu', 'tidecon'으로 저장되어 있다. 위도는 동일지점이니 조화분해에 입력했던 그대로 입력하면 되며, 시간은 예측하려는 기간을 datetime64 형태로 입력하면 된다. 또한, t_predic에 들어가는 예측시간인 t_time은 이전 t_tide에 사용했던 datetime 형식이 아닌 numpy의 datetime64형태로 변환해줘야 한다.
따라서, 아래 코드와 같이 nameu, fu, tidecon, xres, t_time을 정의한 뒤, 예측조위인 tprd를 생성하면 된다. 굳이 변수를 정의하지 않고, t_predic 입력변수에 hm_result['변수']와 같이 입력해도 무방하다.
nameu = hm_result['nameu']
fu = hm_result['fu']
tidecon = hm_result['tidecon']
xres = hm_result['xres']
prdtime = np.array(t_time, dtype='datetime64')
tprd = t_predic(prdtime, nameu, fu, tidecon, lat=37.451944, ltype='nodal', synth=0)
그럼 아래 왼쪽과 같이 생산된 예측조위(tprd)를 확인할 수 있고, 원본 관측정보인 t_tidal과 함께 그리면 오른쪽과 같이 나타나게 된다.

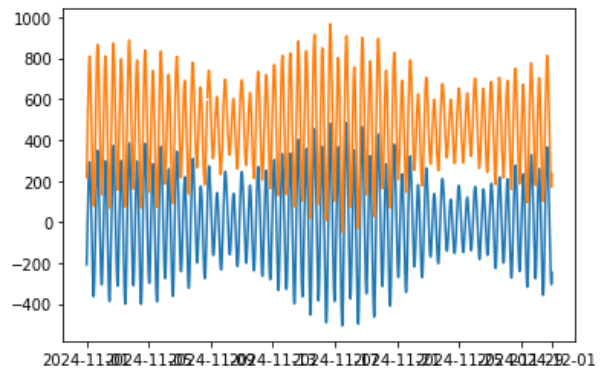
6. 예측조위 검증
예측조위를 생산했으면, 원본정보와 비교하여 검증을 해야한다. 위의 사진을 보면, 예측조위와 관측조위의 진폭차이가 꽤 크게 나는 것처럼 보이는데, 이는 기준이 다르기 때문이다. 관측조위는 DL을 기준으로 한 물높이이지만, 예측조위는 평균해수면인 MSL을 기준으로 위아래의 변동 물높이이다. 따라서, 예측조위에 관측평균해수면 높이만큼 더해줘야 한다. 관측조위의 평균은 466.39이며, 아래 사진과 같이 이를 더해줘서 dl기준의 예측조위인 tprd_dl을 생성한다.

그럼 아래와 같이 예측조위를 생산할 수 있다. 좌측 그림은 두 시계열(관측 - 붉은색, 예측 - 파란색)이며, 오른쪽은 관측과 예측의 차이를 나타낸 그림이다. 예측조위는 관측과 거의 유사한 형태를 보이지만 대조기인 11월 중순경 최대 90cm 이상의 편차를 보이는 것을 확인할 수 있다.


동일한 방법으로 미래의 예측조위를 생산할 수 있다. 위 분석 및 예측은 2024년의 11월 데이터로 수행한 것이다. 따라서 t_predic에 입력할 예측시간을 2024년 12월로 입력한다면, 아래와 같이 12월이 예측 데이터를 생산할 수 있다.
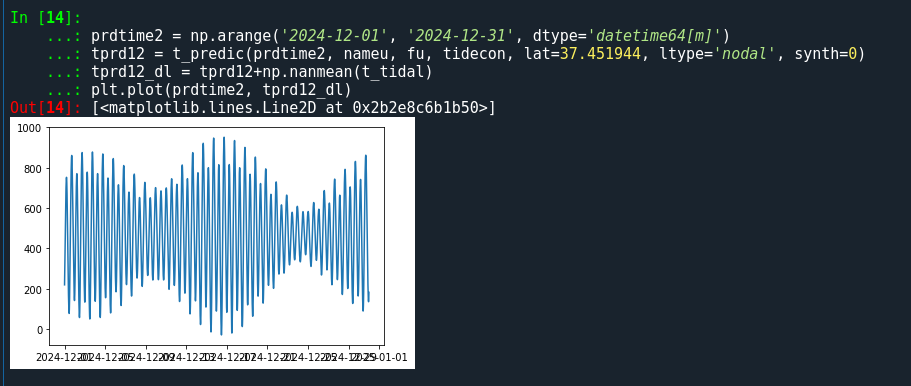
오늘은 파이썬의 t-tide를 활용해 조석 조화분해와 예측조위를 만드는 법에 대해 소개해보았다. 다음에는 조위정보가 아닌 해수유동 관측정보를 활용하여 조류조화분해를 하는 방법에 대해 소개해보도록 하겠다.
'자료분석 및 코딩 > 파이썬' 카테고리의 다른 글
| [조화분해] 파이썬을 활용한 조화분해(harmonic analysis) - 3. 조류조화분해 (0) | 2025.01.17 |
|---|---|
| [파이썬] 유속, 풍속(speed) & 유향, 풍향(degree)의 U, V 변환 (4) | 2025.01.03 |
| [조화분해] 파이썬을 활용한 조화분해(harmonic analysis) - 1. 조화분해란 (0) | 2024.12.31 |
| [파이썬] 해양수치모델 검증 - 1. nc 파일읽기, 특정 지점(위치) 찾기, 최근접 격자 찾기 (1) | 2024.04.30 |
| [파이썬] 해양수치모델 시간 형식 변환. GMT, UTC, KST, 그리니치, 줄리안 데이 변환 (0) | 2023.06.30 |